
As enterprises scale their digital operations, visibility into their data landscape becomes a strategic priority. Modern businesses generate and consume data across cloud platforms, legacy systems, APIs, and third-party tools, yet many struggle to answer a simple question: What data do we have, and where is it?
This is where data catalogs come into play. Traditionally, data catalogs served as searchable indexes of available datasets, detailing schema, lineage, and basic metadata. But in 2025, that’s no longer enough. The rise of artificial intelligence, self-service analytics, and enterprise-wide data literacy demands a smarter, more contextual approach. Enter the next-generation data catalog: AI-augmented, knowledge-driven, and deeply integrated with operational workflows.
From Metadata to Meaning
Modern data catalogs now incorporate active metadata, behavioral signals, and usage intelligence. Instead of simply showing where data is stored, they reveal how data is used, by whom, and for what purpose. This shift, from static inventory to living knowledge graph, enables organizations to surface insights, detect anomalies, and recommend data assets in real time.
Imagine a product manager searching for customer churn data. Instead of parsing through endless tables, a smart data catalog might suggest the marketing team’s most frequently used churn dataset, highlight related dashboards, show lineage to the data pipeline, and even flag quality issues. This contextual discovery dramatically accelerates time-to-insight.
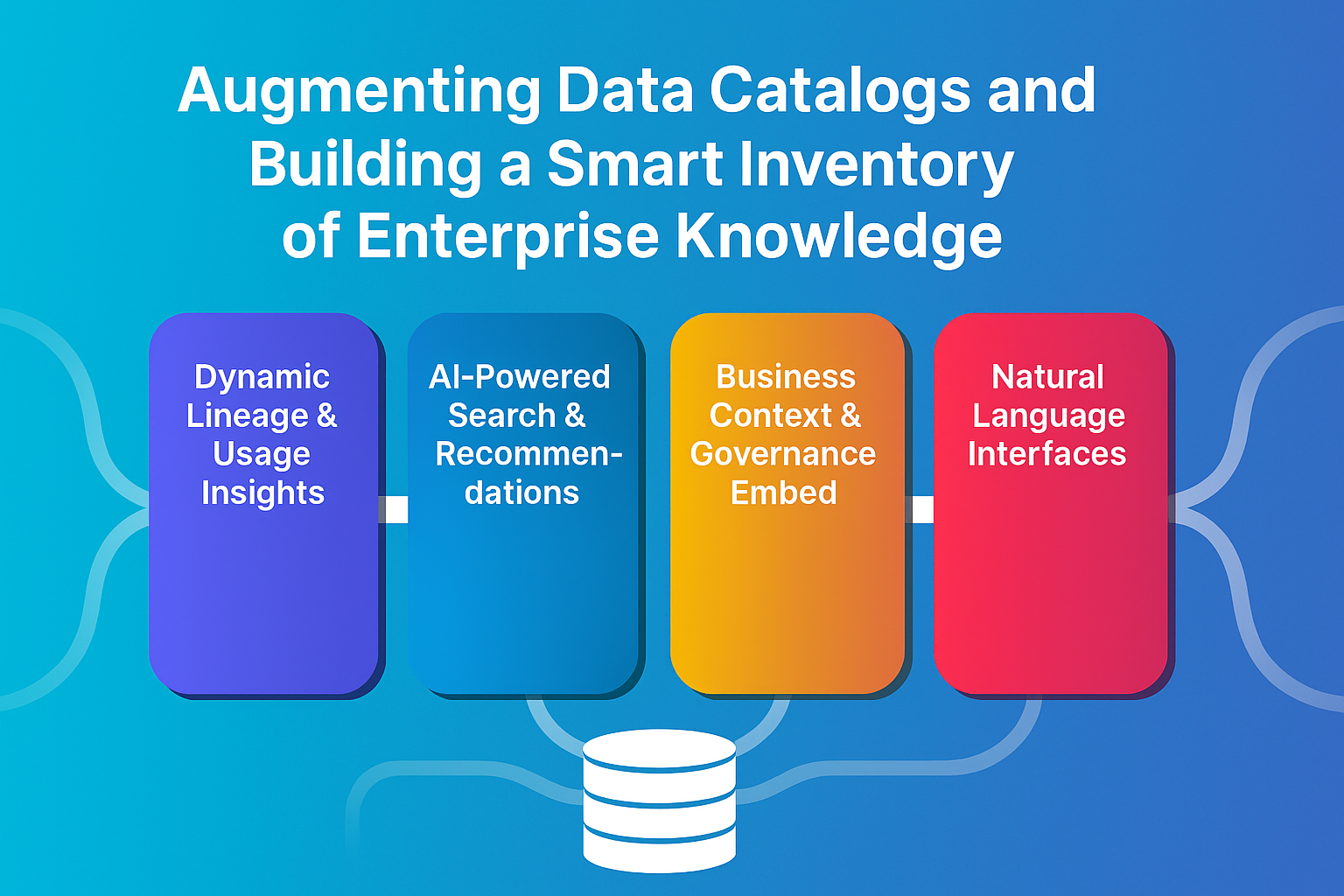
Building a Smart Inventory
To create a true knowledge inventory, enterprises are now:
- Ingesting multi-source metadata: From warehouses, lakes, SaaS tools, and code repositories.
- Layering in usage patterns: Tracking queries, lineage, access logs, and downstream dependencies.
- Enriching with business context: Adding definitions, ownership, and compliance tags.
- Enabling AI-powered search: Using natural language queries and semantic discovery.
- Encouraging crowd-sourced intelligence: Letting users annotate, rate, and recommend assets.
This smart inventory acts as a single source of truth, not just for data engineers but also for analysts, product teams, compliance officers, and executives.
Driving Knowledge with Automation
AI plays a central role in turning data catalogs into active knowledge engines. Machine learning models can classify data, detect sensitive fields, auto-tag assets, and map lineage dynamically. Natural language interfaces make exploration intuitive, while recommendation systems surface relevant datasets or dashboards based on past behaviors and role context.
This automation also aids governance. Policies can be embedded at the catalog level—automatically flagging PII, enforcing access controls, or detecting drift in data quality. Rather than being a passive tool, the catalog becomes a proactive agent in enterprise data stewardship.
Unlocking Value Across the Business
A smart data catalog is not just an IT asset. It’s a business enabler. Product teams can speed up experimentation. Finance can trace KPIs to trusted sources. Compliance can confidently audit lineage and access. And executives gain transparency into how data drives decisions.
By connecting data assets to business outcomes, organizations foster a culture where knowledge is shared, not siloed, and where decisions are made with clarity, not guesswork.
Leave a Reply